本文共 3623 字,大约阅读时间需要 12 分钟。
一、前言
”精准营销”现在已经被大家熟知,并且成为各公司非常看重和依赖的营销模式,那么怎么才能在海量的数据里面精准找出人群去进行投放,相信每个公司都有一套不同的实现。苏宁易购作为一家大型智慧零售企业,“精准营销”在集团业务中承担着重要的角色,每天会生产数以万计的人群包,尤其是在大促中,更是承担着重要的责任,那么怎么保证快速、准确的生成人群包,满足业务的需要,下面是我们对生成人群包的技术的一些思考及演进过程,希望能让大家收获一些东西。本文推荐技术总监、架构师、技术经理、开发工程师等群体阅读。
二、业务介绍及面临挑战
业务场景分析
精准营销模式可以概括为5W营销分析框架,在合适的时机(When),将合适的业务(Which),通过合适的渠道(Where),采取合适的行动(What),营销合适的用户(Who),在整个过程中贯彻“以客户为中心”的理念,实现营销管理的持续改善,其中营销合适的用户即生成人群包,选出的人群是否精准直接决定着此次营销活动的成败。
生成人群包作为营销活动的生产引擎,其生产功率的大小和精准性,决定着生产人群包的效率与价值,效率和精准性对每天营销活动很多的公司来说尤为重要,我司生成的人群包主要分为线上人群包及线下人群包,当然线上会员和线下会员已融会贯通,线上会员可以通过精准定位及活动引流到线下,线下会员也可通过活动引流到线上,实现线上线下会员真正融合。每个营销活动的目的都是不一样的,那么它所关注的人群就不一样的,那么当然圈出人群的条件就是千变万化的,我们通过标签化用户特征行为,然后固化下来并及时更新的标签,来作为筛选人群的条件,通过标签来筛选出所要的人群,并进行投放。当然,这只是我们其中的一种筛选人群的方法,不同的业务不同的场景来锁定目标人群的方法都是不一样的。
挑战
- 海量用户在生产人群包的的时候需要从几亿甚至数十亿的用户中筛选出你所需要的会员,怎么能做到快速准确。
- 千变万化的条件组合每个营销活动的目的不一样,就导致筛选人群的条件不一样,怎样才能支持各种条件的互相组合。
- 数以万计的人群包每天要处理数以万计的人群包,怎么保证在业务可接受的时间处理出来。
- 系统的扩展性如何保证系统的扩展性,在存储资源、计算资源、以及存储形式上才能满足业务的持续扩展。
三、技术演进
生产人群包的技术演进主要经过了3个阶段:
1. 大数据hive任务创建
此技术方案是通过运用大数据平台(后面简称ide)的存储计算能力来实现人群包的生产和投放,其中主要分为三块:业务系统负责人群条件的筛选;大数据系统负责进行存储计算,投放系统负责发进行投放;
业务系统主要承担后台的功能,为营销人员提供创建人群包的后台界面,使业务能通过一些界面化的一些操作就能生成人群,其将筛选的人群条件通过调用大数据平台的接口生成计算任务,得到计算结果即人群包。其主要的技术架构如下:
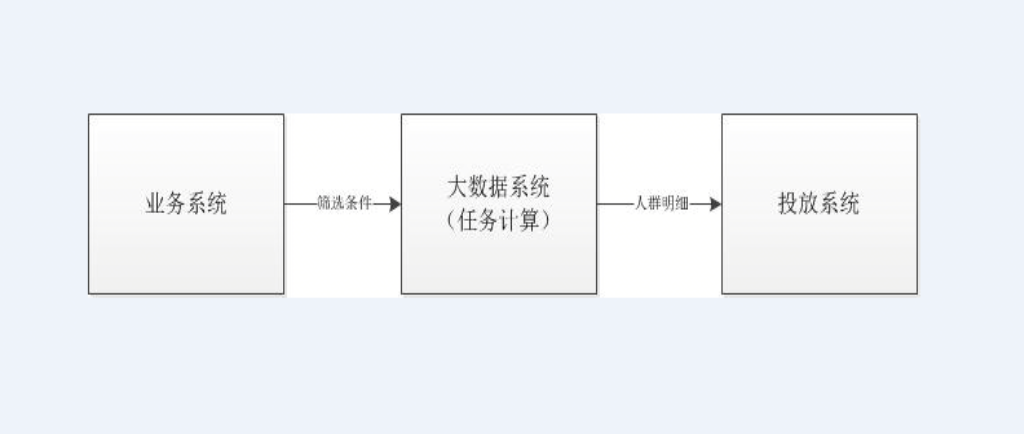
该技术方案分析:
通过创建任务的方式,在cbt(大数据计算平台)上一个人群包创建一个计算任务,当人群包的数量越来越多的时候,将造成任务数量越来越多,计算资源需求也越来越多,机器资源总是有限的,就会造成计算瓶颈,延长人群包的生成时间。
动态的创建任务对大数据平台的调度及稳定性造成了一定的影响,不能因一个系统的业务而增加公共系统不稳定的风险
针对以上问题,我们在技术实现方案上提出了一些优化的设想:
hive是把所有的数据拿过来进行计算,而且没有索引的机制,我们为什么不能用索引的方式来增加计算速度,原来用几分钟算好一个人群包,通过索引的方式是否能达到秒级,这样处理人群包速度就会有大的提升,在业务要求的时间内用更少的资源来完成更多的计算。
通过增加消息中间件来实现业务系统与ide的解耦。
2. Spark + ES
此技术方案是采用kafka将业务系统跟ide解耦,然后通过sparkStreaming来消费kafka中的数据存储到hive表中,然后创建一个spark的任务来分批获取hive表中的数据,然后在driver端多线程的根据条件来查询es(ElasticSearch)并将最终结果存储到hive表中,相当于一个driver多组并行的excutor,提高生产人群包的并发度,加快人群包的生产速度。其生产人群包的速度是原先的几十倍,乃至上百倍,相比于第一个方案,性能有了质的飞越,并且使用的机器资源有了大幅度的降低。
Spark 天生支撑ES(ElasticSearch)的查询,有现成的封装代码,使用起来非常简单,基本上是一个查询中一个分片一个excutor,有助于项目的快速启动及实现,而且es(ElasticSearch)是分布式搜索引擎,可动态扩展,采用多副本容灾,保证了系统的健壮性,及其可扩展性。
其主要的技术架构如下:
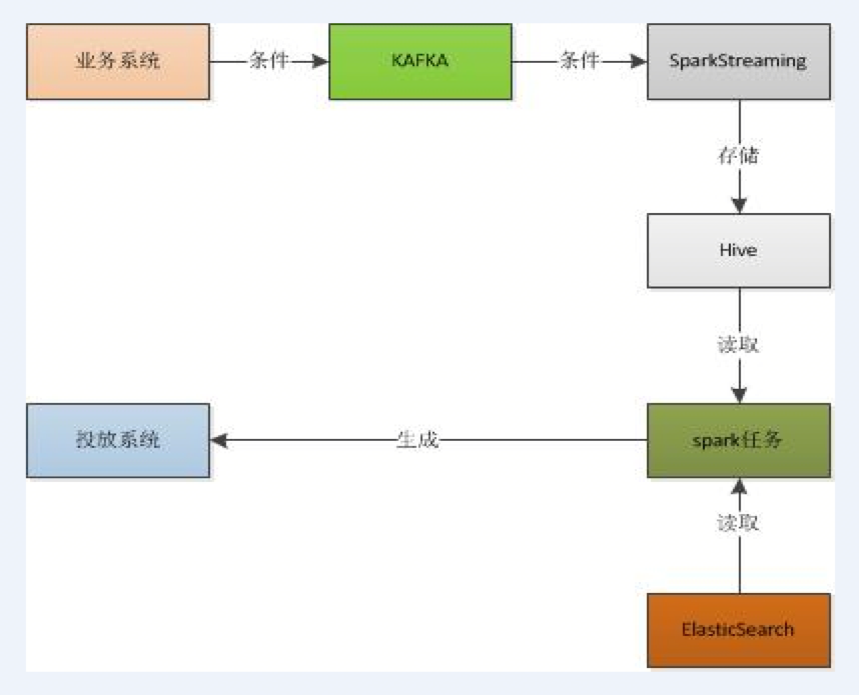
该技术方案分析如下:
由于采用es(ElasticSearch)作为数据的存储及查询引擎,当新增一个或几个字段的时候,要重新往进灌数据,而且es(ElasticSearch)中存储的是全量的索引数据故重新灌一遍数据需要很长的时间。
es(ElasticSearch)中的mapping字段越来越多的情况下会对创建索引及检索的速度产生影响,使性能下降很快
通过es(ElasticSearch)聚合人群预估人数的时候查询很慢要达到秒级。3. Spark + pg + roaringbitmap
Roaringbitmap 是一种十分优秀的压缩位图索引,被广泛用于数据库和搜索引擎中,通过利用位级并行,它们可以显著加快查询速度。因此,我们将elasticsearch换成了PostgreSQL + roaringbitmap插件,来提高我们的查询速度,我们采用将用户和标签形成倒排方式进行存储,也就是一个标签里边包含所有拥有这个标签的用户,用户形成一个roaringbitmap,通过roaringbitmap的交并差,形成最终的人群。
其主要的技术架构如下:
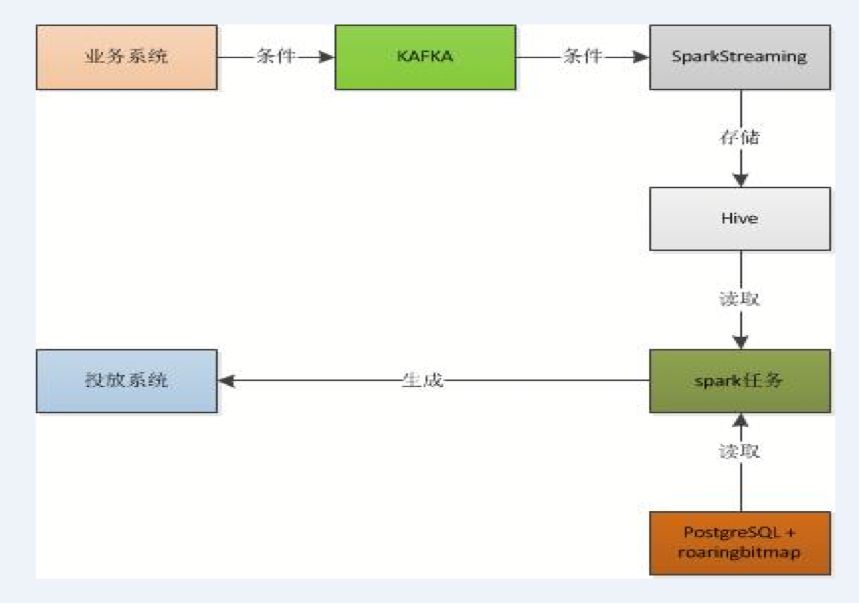
该技术方案解决了第二种方案里增加字段的难题,基本上实现了业务的无限扩展,并提升了查询的响应速度,这套方案也是我们苏宁目前正在运行生成人群包的技术方案,为各大促及日常营销活动提供了强有力的支撑。
四、踩过的那些坑
1. 向同一个hive表中insert into数据
第二种方案中当全量人群包计算的时候会向同一个hive表中插入不同的人群包数据,而且是并行插入,在最开始的时候很快到后面越来越慢,基本情况如图:
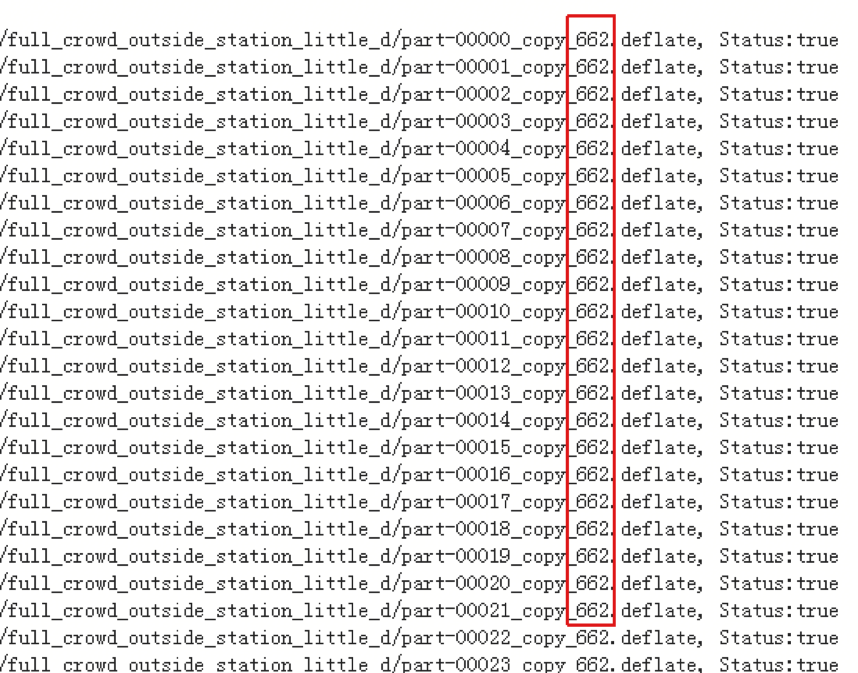
后来我们针对这种情况进行了优化,采用分区的方法来进行解决,也就是按照人群包的id进行分区,每个人群包的人群数据存储到一个独立的分区上,修改完成后存储性能得到了极大的提升。
2. Es中_source设置,在查询人群明细时减少io
_source是一个自动生成的字段, 用来存储实际提交的JSON数据, 他是不索引的(不可搜索), 只是用来存储。 在执行\u0026quot;fetch\u0026quot;类的请求时, 比如get或者search, _source字段默认也会返回。这个存储十分的占用磁盘空间,而且在进行大批量检索时会非常的占用磁盘io。
因为我们只需要返回用户id故对_source字段进行了设置,让其只保存用户id,这样既节省了存储空间又减少了查询时磁盘io过大的问题。设置如下图:

3. Spark 任务读取es人群详细数据时 driver oom
Spark生成人群包的任务,在运行一段时间后出现oom(out of memory),刚开始的时候也没有注意以为是内存不够,直接增加内存,但是增加内存之后,后面还是不间断的出现oom(out of memory)现象,后面进行分析发现,spark在读取es(ElasticSearch)数据的时候会将一些配置信息、dsl(Domain Specific Language)等存储到driver端,当并行获取很多个人群包详细信息的时候就会把内存打满,后面我们在driver端将开启的线程数降低,解决了次问题。
五、总结
以上内容就是我们生成人群包的一些技术实践,通过不同技术方案的持续优化和改进来满足业务提出的目标,为企业创造更大的价值,减少无谓的资源浪费,这就是我们技术人存在的价值。我们会持续的优化改进下去,技术方案的改进和优化就像一场没有终点的马拉松,永远在路上。在这里只是给大家抛砖引玉,当前方案中如果有什么不对或者不足的地方,欢迎提出来我们一起探讨改进。
作者:
王志伟,苏宁易购IT总部大数据中心标签研发部部门负责人,对推荐系统、精准化营销及高并发、高流量应用等方面的架构及研发有着深刻的理解及实战经验,拥有6年以上相关领域经验。目前负责苏宁易购标签平台、精准化营销的工作,多次主导大型促销活动推荐系统、精准化营销性能优化,对标签、推荐、精准化营销有着深刻的认知。转载地址:http://wawux.baihongyu.com/